
# 安装
Scrapy 是一个十分强大的爬虫框架,使用 pip 来安装 scrapy 需要安装大量的依赖库,至少需要的依赖库有 Twisted,lxml,pyOpenSSL。而在不同平台环境又各不相同,所以推荐使用 anaconda 来进行安装 scrapy:
conda install scrapy
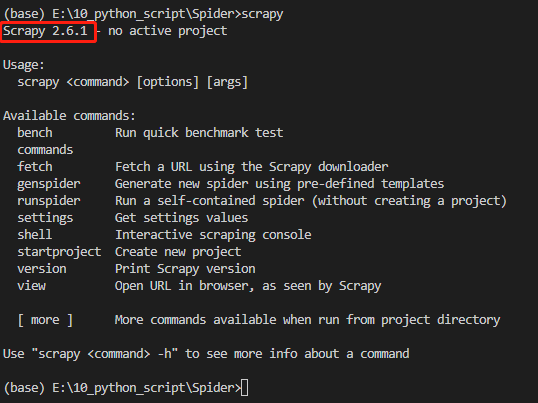
测试是否安装成功,在命令行输入 scrapy,显示出版本号即安装成功。
# 相关链接
官网 (opens new window) github (opens new window) 官方文档 (opens new window) 中文文档 (opens new window)
# 开始使用
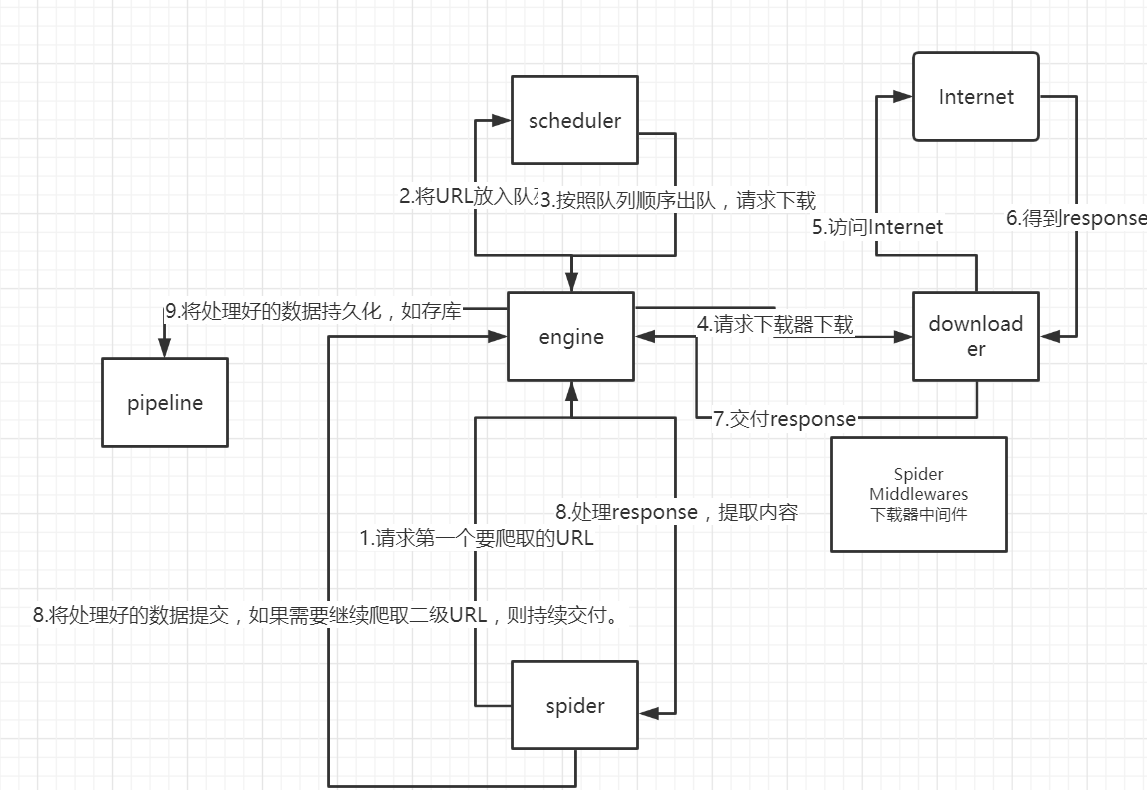
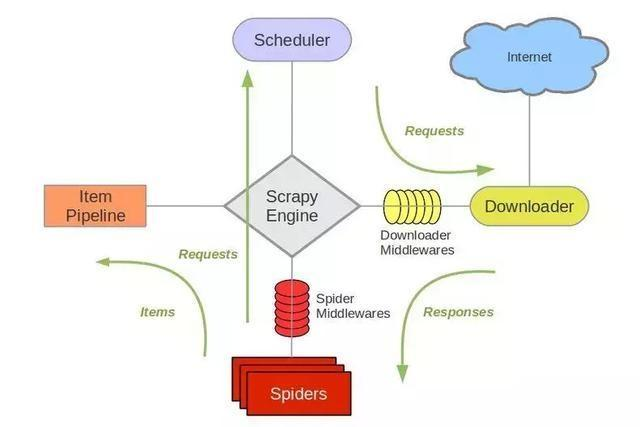
# 整体架构
本图按顺序说明整个程序执行时候发生的顺序。
注意在调用下载器时,往往有一个下载器中间件,使下载速度提速。
官网架构图
# 创建项目
在开始抓取之前,必须建立一个新的项目。在命令行中输入如下代码:
scrapy startproject tutorial
这将创建一个 tutorial 目录包含以下内容:
tutorial/
scrapy.cfg # deploy configuration file
tutorial/ # project's Python module, you'll import your code from here
__init__.py
items.py # project items definition file
middlewares.py # project middlewares file
pipelines.py # project pipelines file
settings.py # project settings file
spiders/ # a directory where you'll later put your spiders
__init__.py
2
3
4
5
6
7
8
9
10
# 第一只蜘蛛
Spiders 是我们定义的类,Scrapy 会从一个网站(或一组网站)中抓取信息。我们需要定义初始请求地址,可选的是如何跟随页面中的链接,以及如何解析下载的页面内容和提取数据。
这是我们第一只蜘蛛的代码。将其保存在名为的文件中 quotes_spider.py 下 tutorial/spiders 项目中的目录:
import scrapy
class QuotesSpider(scrapy.Spider):
name = 'quotes'
start_urls = [
'https://quotes.toscrape.com/tag/humor/',
]
def parse(self, response):
for quote in response.css('div.quote'):
yield {
'author': quote.xpath('span/small/text()').get(),
'text': quote.css('span.text::text').get(),
}
next_page = response.css('li.next a::attr("href")').get()
if next_page is not None:
yield response.follow(next_page, self.parse)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
如上,我们的 Spider 子类 scrapy.Spider 并定义了一些属性和方法:
name :标识蜘蛛。它在一个项目中必须是唯一的,即不能为不同的爬行器设置相同的名称。
start_requests() :必须返回请求的可迭代(你可以返回请求列表或编写生成器函数),爬行器将从该请求开始爬行。后续请求将从这些初始请求中相继生成。
parse() :将被调用以处理为每个请求下载的响应的方法。Response 参数是 TextResponse 它保存页面内容,并具有进一步有用的方法来处理它。
这个 parse() 方法通常解析响应,将抓取的数据提取为字典,还查找要遵循的新 URL 并创建新请求 (Request )。
# 如何运行我们的蜘蛛
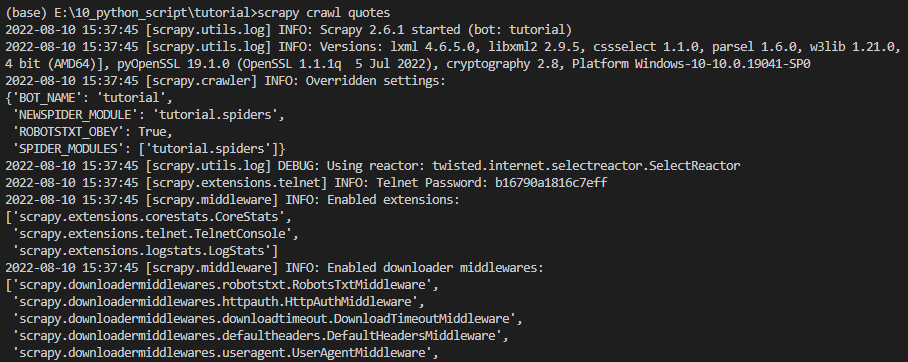
要使蜘蛛正常工作,请转到项目的顶级目录并运行:
scrapy crawl quotes
此命令会运行我们刚刚添加的名为 quotes 的 spider ,会发送一些请求到 quotes.toscrape.com 网址。将得到类似于以下内容的输出:
# 在后台发生了什么?
Scrapy 调度 Spider 的方法 scrapy.Request 返回的对象。start_requests 在收到每个响应的响应后,它会实例化 Response 对象并调用与请求关联的回调方法(在本例中为 parse 方法),将响应作为参数传递。
# 启动 start_requests 的快捷方式
无需实现 start_requests() 方法,该方法生成 scrapy.Request 对象,我们可以只定义一个具有 url 列表的 start_urls 的类属性。这些 url 列表会被 start_requests() 方法作为默认参数来使用:
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
start_urls = [
'http://quotes.toscrape.com/page/1/',
'http://quotes.toscrape.com/page/2/',
]
def parse(self, response):
page = response.url.split("/")[-2]
filename = f'quotes-{page}.html'
with open(filename, 'wb') as f:
f.write(response.body)
2
3
4
5
6
7
8
9
10
11
12
调用 parse() 方法来处理这些 URL 的每个请求,即使我们还没有显式地告诉 Scrapy 这样做。发生这种情况是因为 parse() 是 Scrapy 的默认回调方法。
# 提取数据
# 安装 pyquery
这里不使用 scrapy 自带的 css 选择器和 XPath 表达式,使用和 jquery 语法一样的 pyquery,首先使用 anaconda 安装 pyquery:
conda install pyquery
# 提取名言和作者
我们待提取的 html 结构如下:
<div class="quote">
<span class="text"
>“The world as we have created it is a process of our thinking. It cannot be changed without
changing our thinking.”</span
>
<span>
by <small class="author">Albert Einstein</small>
<a href="/author/Albert-Einstein">(about)</a>
</span>
<div class="tags">
Tags:
<a class="tag" href="/tag/change/page/1/">change</a>
<a class="tag" href="/tag/deep-thoughts/page/1/">deep-thoughts</a>
<a class="tag" href="/tag/thinking/page/1/">thinking</a>
<a class="tag" href="/tag/world/page/1/">world</a>
</div>
</div>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
使用 pyquery 把名言、作者和标签提取出来:
from pyquery import PyQuery as pq
doc = pq(response.body)
for quote in doc('.quote').items():
text = quote('.text').text()
author = quote('.author').text()
tags = quote('.tags .tag').text().split(' ')
print(dict(text=text, author=author, tags=tags))
# 输出:
{'text': '“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”', 'author': 'Albert Einstein', 'tags': ['change', 'deep-thoughts', 'thinking', 'world']}
{'text': '“It is our choices, Harry, that show what we truly are, far more than our abilities.”', 'author': 'J.K. Rowling', 'tags': ['abilities', 'choices']}
2
3
4
5
6
7
8
9
10
11
12
# 在 Spider 中提取数据
目前为止,Spider 并没有提取任何数据,只是将整个 HTML 页面保存到本地文件中。接下来把上面的提取逻辑集成到 Spider 中。
Scrapy 的蜘蛛通常会生成许多字典,其中包含从页面中提取的数据。所以在回调中使用 Python 关键字 yield,如下所示:
import scrapy
from pyquery import PyQuery as pq
class QuotesSpider(scrapy.Spider):
name = "quotes"
start_urls = [
'https://quotes.toscrape.com/page/1/',
'https://quotes.toscrape.com/page/2/',
]
def parse(self, response):
for quote in quotes.items():
yield {
'text': quote('.text').text(),
'author': quote('.author').text(),
'tags': quote('.tags .tag').text().split(' '),
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
运行上面的蜘蛛,会输出如下提取的数据和日志::
# 存储抓取的数据
存储抓取数据的最简单方法是使用 Feed exports ,使用以下命令:
scrapy crawl quotes -O quotes.json
# 或者保存为csv
scrapy crawl quotes -O quotes.csv
# 解决中文乱码
scrapy crawl quotes -O quotes.json -s FEED_EXPORT_ENCODING=utf-8
2
3
4
5
这将生成一个quotes.json包含所有抓取项目的文件,并以JSON序列化。若出现中文乱码,则添加-s FEED_EXPORT_ENCODING=utf-8即可。
命令行-O(大写的O)开关覆盖任何现有文件;而是使用-o(小写的o)将新内容附加到任何现有文件。但是,附加到 JSON 文件会使文件内容无效 JSON。附加到文件时,请考虑使用不同的序列化格式,例如JSON Lines:
scrapy crawl quotes -o quotes.jl
JSON Lines格式很有用,因为它类似于流,你可以轻松地将新记录附加到它。当你运行两次时,它没有同样的 JSON 问题。此外,由于每条记录都是单独的一行,因此你可以处理大文件而无需将所有内容都放入内存中,有JQ之类的工具可以在命令行中帮助执行此操作。
在小型项目(如本教程中的项目)中,这应该足够了。但是,如果你想对抓取的项目执行更复杂的操作,你可以编写一个Item Pipeline。创建项目时,已为你设置了 Item Pipelines 的占位符文件,在 tutorial/pipelines.py. 如果你只想存储抓取的项目,则不需要实现任何项目管道。
# 跟踪链接
如果不光是想从 https://quotes.toscrape.com 的前两页中抓取,而是想从网站的所有页面中抓取内容,那么就需要跟踪链接。
首先是提取我们关注页面的链接。检查页面,可以看到有一个链接上面带有前往下一页的标记:
<ul class="pager">
<li class="next">
<a href="/page/2/">Next <span aria-hidden="true">→</span></a>
</li>
</ul>
2
3
4
5
把这个标记提取出来:
next_page = doc('.pager .next a').attr('href')
然后把Spider修改为递归地跟随到下一页的链接,然后从中提取数据:
import scrapy
from pyquery import PyQuery as pq
class QuotesSpider(scrapy.Spider):
name = "quotes"
start_urls = [
'https://quotes.toscrape.com/page/1/',
]
def parse(self, response):
for quote in quotes.items():
yield {
'text': quote('.text').text(),
'author': quote('.author').text(),
'tags': quote('.tags .tag').text().split(' '),
}
next_page = doc('.pager .next a').attr('href')
if next_page is not None:
next_page = response.urljoin(next_page)
yield scrapy.Request(next_page, callback=self.parse)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
在提取数据后,该parse()方法查找到下一页的链接,使用该 urljoin()方法构建一个完整的绝对 URL(因为链接可以是相对的)并产生一个到下一页的新请求,将自己注册为回调来处理下一页的数据提取并保持爬取通过所有页面。
你在这里看到的是 Scrapy 的以下链接机制:当你在回调方法中产生一个请求时,Scrapy 将安排发送该请求并注册一个回调方法以在该请求完成时执行。
使用它,你可以构建复杂的爬虫,根据你定义的规则跟踪链接,并根据它访问的页面提取不同类型的数据。
在我们的示例中,它创建了一种循环,跟踪所有指向下一页的链接,直到找不到一个——这对于爬取博客、论坛和其他带有分页的站点非常方便。
# 创建请求的快捷方式
作为创建请求对象的快捷方式,可以使用 response.follow:
import scrapy
from pyquery import PyQuery as pq
class QuotesSpider(scrapy.Spider):
name = "quotes"
start_urls = [
'https://quotes.toscrape.com/page/1/',
]
def parse(self, response):
for quote in quotes.items():
yield {
'text': quote('.text').text(),
'author': quote('.author').text(),
'tags': quote('.tags .tag').text().split(' '),
}
next_page = doc('.pager .next a').attr('href')
if next_page is not None:
yield response.follow(next_page, callback=self.parse)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
与 scrapy.Request 不同,response.follow直接支持相对 URL - 无需调用 urljoin。注意response.follow只返回一个 Request 实例;你仍然需要提交这个请求。
你还可以将选择器传递给response.follow而不是字符串;这个选择器应该提取必要的属性:
for href in response.css('ul.pager a::attr(href)'):
yield response.follow(href, callback=self.parse)
2
对于<a>元素有一个快捷方式:response.follow自动使用它们的 href 属性。所以代码可以进一步缩短:
for a in response.css('ul.pager a'):
yield response.follow(a, callback=self.parse)
2
要从一个可迭代对象创建多个请求,你可以 response.follow_all改用:
anchors = response.css('ul.pager a')
yield from response.follow_all(anchors, callback=self.parse)
2
或者,进一步缩短它:
yield from response.follow_all(css='ul.pager a', callback=self.parse)
# 更多示例和模式
这是另一个蜘蛛,它说明了回调和以下链接,这次是为了抓取作者信息:
import scrapy
class AuthorSpider(scrapy.Spider):
name = 'author'
start_urls = ['https://quotes.toscrape.com/']
def parse(self, response):
author_page_links = response.css('.author + a')
yield from response.follow_all(author_page_links, self.parse_author)
pagination_links = response.css('.pager .next a')
yield from response.follow_all(pagination_links, self.parse)
def parse_author(self, response):
doc = pq(response.body)
yield {
'name': doc('.author-title').text(),
'birthdate': doc('.author-born-date').text(),
'address': doc('.author-born-location').text(),
'bio': doc('.author-description').text(),
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
这个蜘蛛会从主页开始,它会跟随到所有作者页面的链接,在每个作者页面调用回调函数parse_author,来抓取作者信息。
# 使用蜘蛛参数
可以在运行Spider时使用 -a 选项提供命令行参数:
scrapy crawl quotes -O quotes-humor.json -a tag=humor
这些参数被传递给 Spider 的__init__方法并默认成为 Spider 的属性。
示例中,为tag参数提供的值将通过self.tag传递进去。可以使用它让蜘蛛仅获取带有特定标签的信息,并根据参数构建 URL:
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
def start_requests(self):
url = 'https://quotes.toscrape.com/'
tag = getattr(self, 'tag', None)
if tag is not None:
url = url + 'tag/' + tag
yield scrapy.Request(url, self.parse)
def parse(self, response):
for quote in response.css('div.quote'):
yield {
'text': quote.css('span.text::text').get(),
'author': quote.css('small.author::text').get(),
}
next_page = response.css('li.next a::attr(href)').get()
if next_page is not None:
yield response.follow(next_page, self.parse)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
如果将tag=humor参数传递给这个蜘蛛,那么它只会访问来自humor标签的 URL,例如 https://quotes.toscrape.com/tag/humor
# 结尾
本教程只介绍 Scrapy 的基础知识,还有很多其他特性请参考官方文档 (opens new window)的教程。
← python异常处理 mongodb教程 →